Stanford CS224N 深層学習による自然言語処理 Lecture 1 まとめ
前書き
Stanford University CS224Nは深層学習による自然言語処理の授業です。授業のビデオ、使用したスライド、また宿題等、授業のすべてがインタネットで公開されています。
この授業は情報理工の学生だけではなく、言語学の学生も対象となっているため、入門するための前提知識を細々と教えています。自然言語の技術的なところだけではなく、自然言語の本質等のところも触れています。
2019年にまた素人の私はそれを勉強し、実践としてKaggleのコンペで金メダルを取得しました。また、当時はGPT2がすでに出ていて、最後の授業の中で、未来への展望の中で、GPT2が触れていて、将来は巨大なGPTモデルですべての課題が解決されるのではないかとの話がありました。GPT4がNLP業界を席巻している現在から振り返て見ると、当時はこの授業から相当先進なことを学んだ気がします。
一方、それは4年前の授業なので、2023年の今どんなアップデートがあるかは気になります。また、以前勉強会でこの授業が学びましたが、メモなどのことを残らなかったです。そのため、復習兼新しいことのキャッチアップの目的で、CS224N 2023の授業を1回学び直して、各スライドに何を話したかを記録したいと思います。
それでは、最初のLecture 1を始めましょう。

全体のロジ

レクチャーの構成は上のスライドのように、授業の全体像の紹介と言語の概念の紹介を行った上で、本題となるWord2vecの説明を行います。
 授業の基本情報の紹介です。このスライトを無視して良いです。
授業の基本情報の紹介です。このスライトを無視して良いです。

メンバーの構成。このスライトも無視して良いです。
 この授業で教えることは主に3つです。
この授業で教えることは主に3つです。
- ベーシックとなる重要なコンセプト:Word Vector, RNN, Transfromers等。
- 自然言語の全体像、またコンピューターでそれを理解と生成するための難しさ
- NLPの主な課題についてPyTorchでシステムを構築して解決する能力
 またロジの説明です。無視してよいです。
またロジの説明です。無視してよいです。
 宿題は5つあります。 1,2はPythonを使って基礎なプログラミングを行います。3,4,5はPyTorchを使って実際の問題を解決します。
宿題は5つあります。 1,2はPythonを使って基礎なプログラミングを行います。3,4,5はPyTorchを使って実際の問題を解決します。
人間の言語と単語の意味



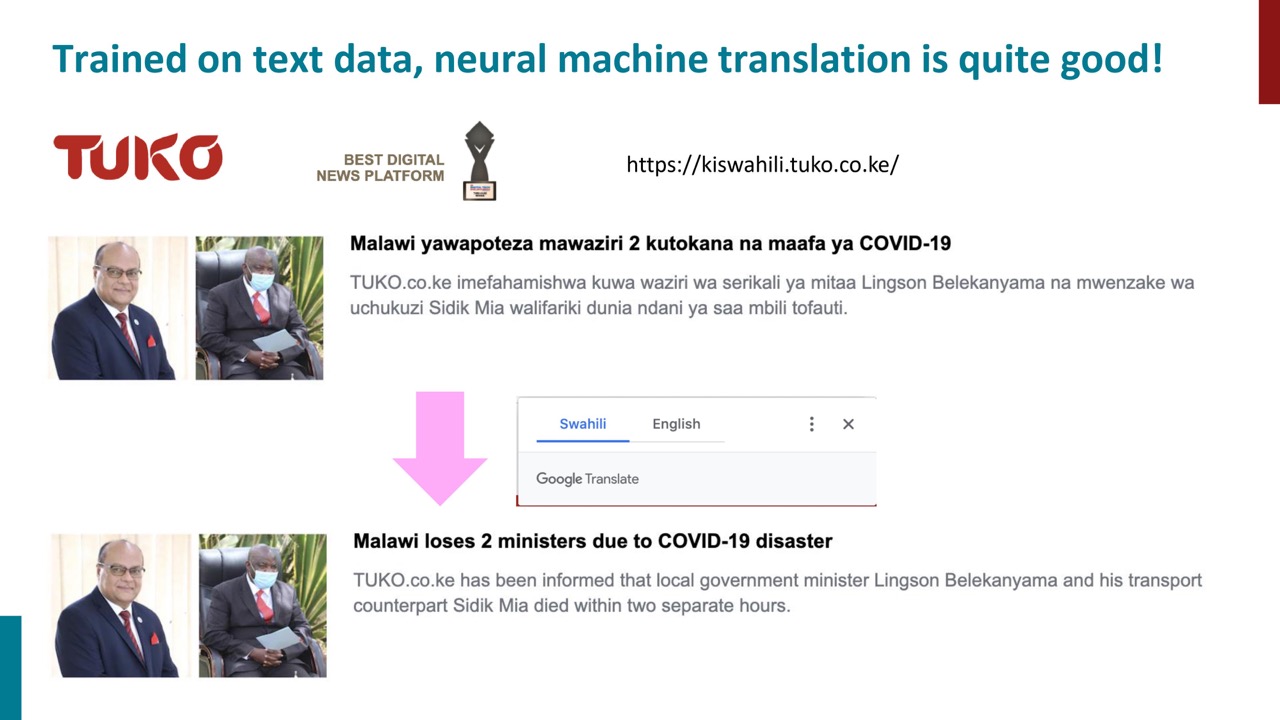 近年の機械翻訳の新しい手法により、機械翻訳はかなり機能するようになりました。 何千年もの間、他の言語を学ぶことは多大な努力を必要とするタスクでしたが、今ではプラウザを開くことで容易にできるようになります。自然言語処理の最大の発展はこのような機械翻訳の進歩です。
近年の機械翻訳の新しい手法により、機械翻訳はかなり機能するようになりました。 何千年もの間、他の言語を学ぶことは多大な努力を必要とするタスクでしたが、今ではプラウザを開くことで容易にできるようになります。自然言語処理の最大の発展はこのような機械翻訳の進歩です。
 OpenAIがリリースしたGPT-3は、ユニバーサルモデルへの第一歩として注目されています。
OpenAIがリリースしたGPT-3は、ユニバーサルモデルへの第一歩として注目されています。
ユニバーサルモデルとは、世界の知識、人間の言語、タスクの実行方法などを学習した大規模モデルです。その一個のモデルで様々なことを行うことができます。
GPT-3には、与えられた例に基づいて特定のタスクを実行する能力もあります。例えば、「窓を割った」という文を「何を割ったか?」という質問に変えるなどです。さらに、GPT-3は人間の言語をSQLに翻訳することも可能で、これによりデータベース操作が容易になります。
 新しく出たChatGPTはより性能がよくたくさんのことができます。
新しく出たChatGPTはより性能がよくたくさんのことができます。

 普通に与えられた自然言語のタスクに対してこなすことができます。例えば、Latexへの変換。
普通に与えられた自然言語のタスクに対してこなすことができます。例えば、Latexへの変換。
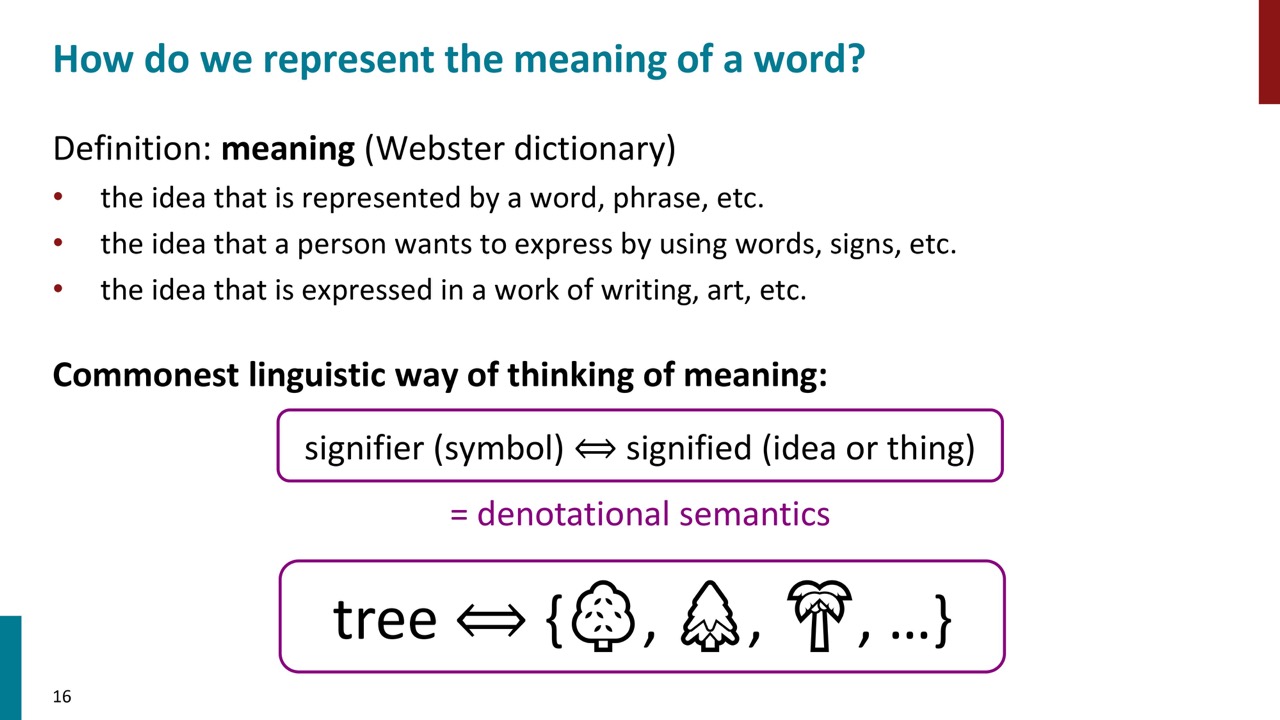 言葉の意味は、言葉(記号や象徴)とそれが指し示すもの(アイデアや物)の間の結びつきとして考えられます。例えば、「椅子」という言葉の意味は、「椅子」の集合体を指します。これは「表示的意味論」(Denotational Semantics)と呼ばれます。
言葉の意味は、言葉(記号や象徴)とそれが指し示すもの(アイデアや物)の間の結びつきとして考えられます。例えば、「椅子」という言葉の意味は、「椅子」の集合体を指します。これは「表示的意味論」(Denotational Semantics)と呼ばれます。
 しかし、この理論を実装するのが難しいため、自然言語処理システムでは、辞書や類語辞典などのリソースを利用して意味を扱 うことが一般的です。特に、同義語の集合や上位語(ISA関係)を組織化したWordNetがよく使われます。上位語を通じて、「パンダ」が「肉食動物」であり、「哺乳動物」であるといった関係性を理解することができます。
しかし、この理論を実装するのが難しいため、自然言語処理システムでは、辞書や類語辞典などのリソースを利用して意味を扱 うことが一般的です。特に、同義語の集合や上位語(ISA関係)を組織化したWordNetがよく使われます。上位語を通じて、「パンダ」が「肉食動物」であり、「哺乳動物」であるといった関係性を理解することができます。
 WordNetなどの人間が構築したツールは、NLPのリソースとして有用ですが、ニュアンスや現代の言葉遣いを十分にカバーしていないという欠点があります。例えば、「proficient」が「good」の同義語としてリストされていますが、これは文脈によりそうではない場合があります。また、新しい用語や現代の俗語は含まれていないため、ツールは常に最新の状態を保つことが難しいです。
WordNetなどの人間が構築したツールは、NLPのリソースとして有用ですが、ニュアンスや現代の言葉遣いを十分にカバーしていないという欠点があります。例えば、「proficient」が「good」の同義語としてリストされていますが、これは文脈によりそうではない場合があります。また、新しい用語や現代の俗語は含まれていないため、ツールは常に最新の状態を保つことが難しいです。
 伝統的なNLPの問題点は、単語を離散的な記号(One-hot vector)として扱うことです。これは、各単語が異なるものとして表現されるため、大量の単語を表現するためには巨大なベクトルが必要となります。例えば、高校英語の辞書には約25万語が含まれていますが、実際の言語にはもっと多くの単語が存在します。したがって、少なくとも50万次元のベクトルが必要となります。
伝統的なNLPの問題点は、単語を離散的な記号(One-hot vector)として扱うことです。これは、各単語が異なるものとして表現されるため、大量の単語を表現するためには巨大なベクトルが必要となります。例えば、高校英語の辞書には約25万語が含まれていますが、実際の言語にはもっと多くの単語が存在します。したがって、少なくとも50万次元のベクトルが必要となります。
 また、単語の類似度も測りにくい問題があります。例えば、ウェブ検索で「Seattle motel」を検索した場合、システムは「Seattle hotel」を含むドキュメントもマッチさせたいと考えます。しかし、One-hot Vectorで単語表現する場合は、ベクトルの内積は0になりまして、類似度を計算できません。
また、単語の類似度も測りにくい問題があります。例えば、ウェブ検索で「Seattle motel」を検索した場合、システムは「Seattle hotel」を含むドキュメントもマッチさせたいと考えます。しかし、One-hot Vectorで単語表現する場合は、ベクトルの内積は0になりまして、類似度を計算できません。
これを解決するための古い方法として、WordNetの同義語を使用したり、意味の重複を持つ単語の表現を構築したりする方法がありましたが、これらは不完全性から大きな失敗を招きました。そこで現代の深層学習方法を紹介します。これは、実数値のベクトルに類似性をエンコードする方法です。

まず分布意味論について紹介します。分布意味論とは、単語の意味をその単語が頻繁に近くに現れる単語によって定義するという考え方です。この考え方は、統計的および深層学習の自然言語処理で広く用いられています。
具体的には、ある単語(例えば「banking」)がテキスト中に現れるたびに、その近くに現れる単語(文脈)を集め、文脈がその単語の意味を表現すると考えます。
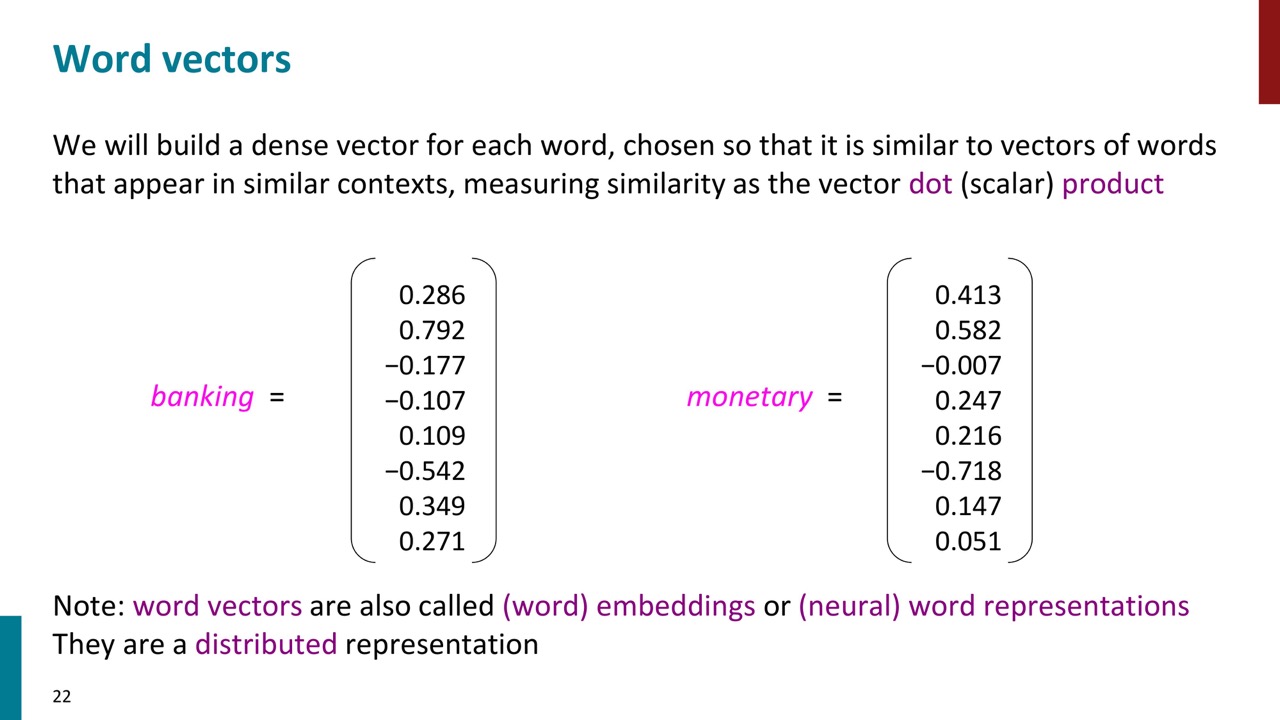 Word Vectorとは、各単語を表す実数値ベクトルのことです。ベクトルは通常300次元で、各単語の意味はその300次元全体に分散しています。中身は実数値なので、単語の類似度をベクトルのDot productで計算できます。
Word Vectorとは、各単語を表す実数値ベクトルのことです。ベクトルは通常300次元で、各単語の意味はその300次元全体に分散しています。中身は実数値なので、単語の類似度をベクトルのDot productで計算できます。
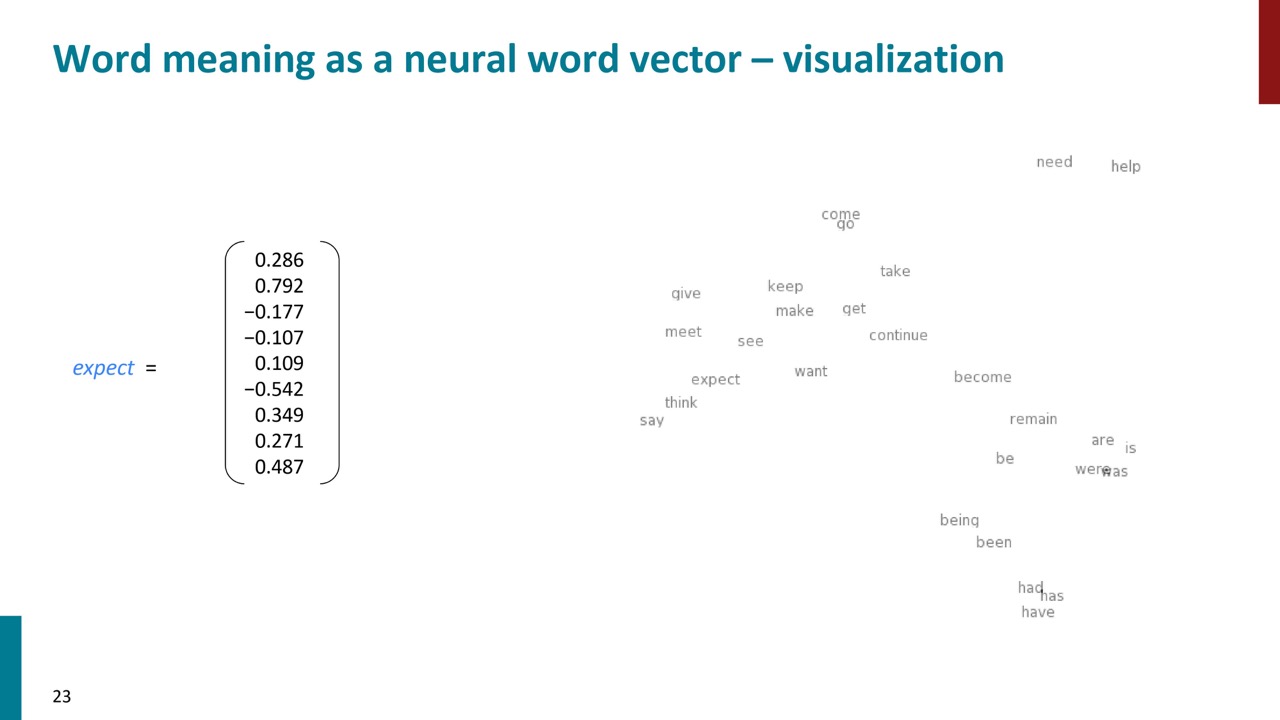 このベクトル空間は、人間が視覚的に理解するのは難しいため、2次元の投影で表示します。この投影により、似たような単語が近くにグループ化されていることがわかります。例えば、国名や国籍を表す単語、動詞などがそれぞれ近くにグループ化されています。このように、分布モデルを用いることで、単語の意味や関連性を表現することが可能になります。
このベクトル空間は、人間が視覚的に理解するのは難しいため、2次元の投影で表示します。この投影により、似たような単語が近くにグループ化されていることがわかります。例えば、国名や国籍を表す単語、動詞などがそれぞれ近くにグループ化されています。このように、分布モデルを用いることで、単語の意味や関連性を表現することが可能になります。
Word2vecの紹介
 word2vecは2013年にTomas Mikolovらから提案した単語のベクトル表現を学習するフレームワークです。
word2vecは2013年にTomas Mikolovらから提案した単語のベクトル表現を学習するフレームワークです。
各単語の良いベクトルを求めるために、大量のテキストから単語ベクトルを学習します。これは、他の単語のコンテキストでどの単語が出現するかを予測する分布的な類似性のタスクを行うことで可能です。具体的には、テキスト中の任意の時点で中心語とその周囲の文脈語を選び、現在のモデルに基づいて文脈語の出現確率を計算します。その後、実際にその中心語の文脈で出現した単語に対して確率を最大化するように単語ベクトルを調整します。
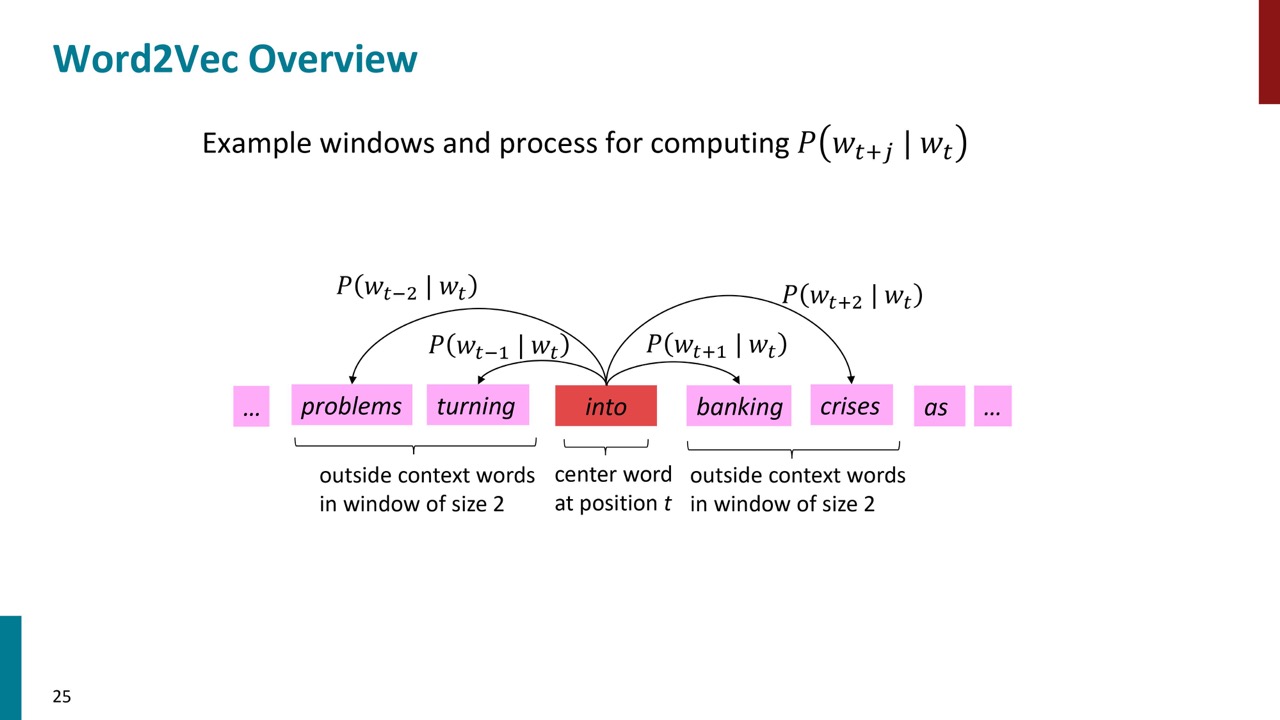
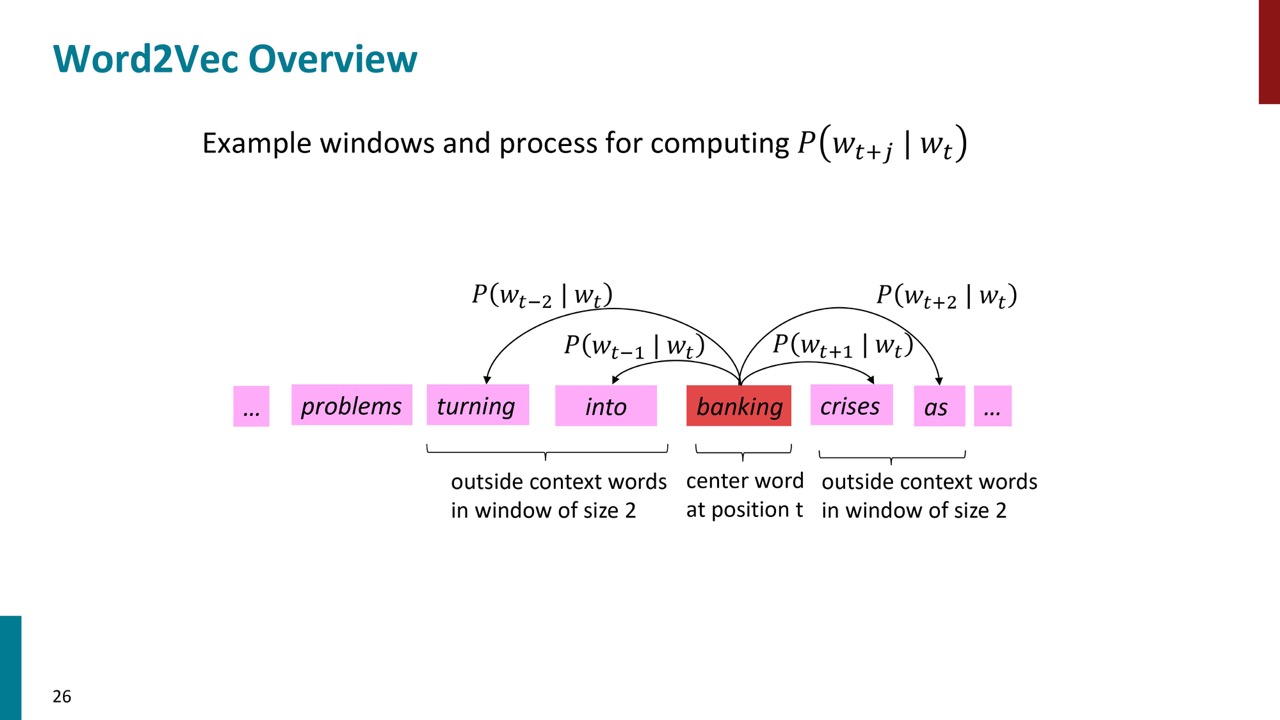
P25とP26はもっと具体的な例です。例えば中心語は「into」の場合は、周りに出ている文脈語の出現確率をモデルにより計算できます。出現確率が高い方が良いです。次にどのようにそのモデルを学習することを説明します。
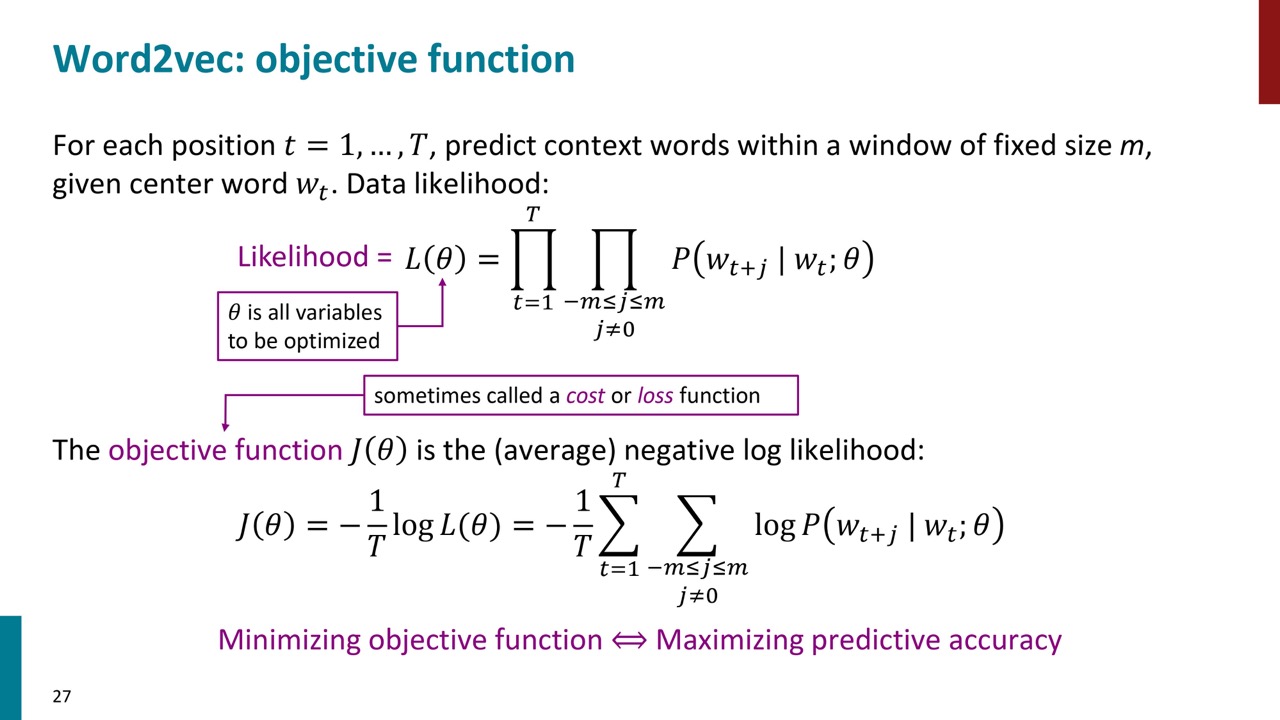 Word2vecがやっていることは、テキストのコーパス内の各位置について、中心の単語WJが与えられた場合、固定サイズMのウィンドウ内の文脈語を予測することです。1個目の式がそれを表しています。θはモデルのパラメーターです。
Word2vecがやっていることは、テキストのコーパス内の各位置について、中心の単語WJが与えられた場合、固定サイズMのウィンドウ内の文脈語を予測することです。1個目の式がそれを表しています。θはモデルのパラメーターです。
コンテキスト内で発生する単語に高い確率を与えたいのです。しかし、標準的な手法に従って、積を扱うよりも和を扱った方が簡単なので、対数尤度を使用します。対数尤度を取ると、すべての積が和に変わります。また、平均対数尤度を扱うため、コーパス内の単語数に対する1/t項をここに追加します。
また、目的関数を最大化するよりも最小化する方が好ましいため、マイナス符号を追加します。したがって、この目的関数J(θ)を最小化することにより、予測精度を最大化することになります。
Word2vec目的関数の最適化
 目的関数がありましたが、文脈語の確率をどう計算するか?それを計算するためには、中心語と文脈語のベクトルを用意して、ピンク色の式で文脈語の出現確率を計算します。P30にでそれの詳細を説明します。
目的関数がありましたが、文脈語の確率をどう計算するか?それを計算するためには、中心語と文脈語のベクトルを用意して、ピンク色の式で文脈語の出現確率を計算します。P30にでそれの詳細を説明します。
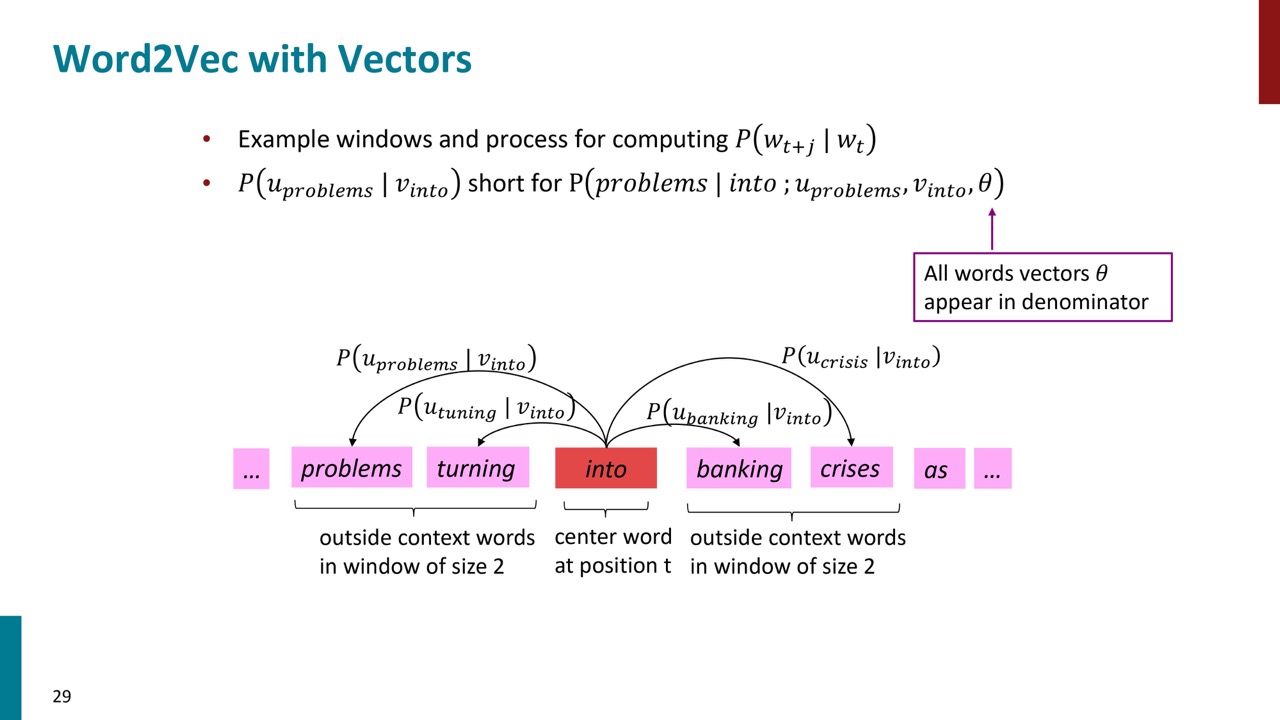
 ①オレンジ色の式は2つの単語ベクトルの内積を取っていることは類似度を測っていることです。
①オレンジ色の式は2つの単語ベクトルの内積を取っていることは類似度を測っていることです。
②内積はマイナスにもなるため、指数をとることで強制にプラスにします。
③分母の部分は、すべての文脈語と中心語との類似度の足し算です。
このようにして、単語間の類似度を確率分布に変換します。例えば、一番望ましい場合は、文脈語と中心語の類似度は1、他の単語と中心語の類似度は0のことです。それ場合のP(O|C)は1になります。
このプロセス全体で使用される関数は「ソフトマックス関数」と呼ばれます。ソフトマックス関数は、任意の実数ベクトルを0から1の範囲の値に変換します。この関数は、大きな値を強調し、最も類似したものに最も多くの確率を割り当てる一方で、何らかの類似性を持つ全てのものに少なくとも何らかの確率を割り当てます。
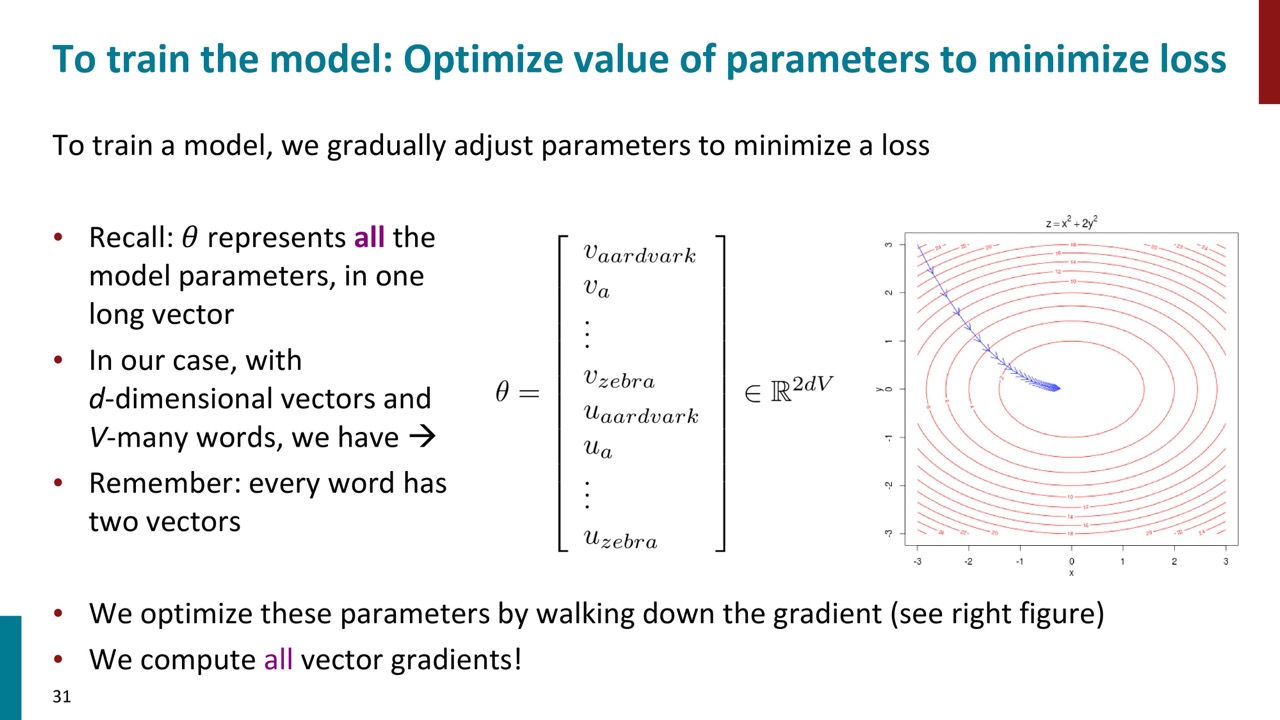 パラメーターを最適化する際に勾配降下法を利用します。
パラメーターを最適化する際に勾配降下法を利用します。
ここでの注意点としては、中心語と文脈語のベクトルが別れていることです。例えば、Zebraという単語にC(Zebra)とO(Zebra)の2つのベクトルがありまして、Zebraは中心語のとこにはC(Zebra)を利用し、文脈語のときはO(Zebra)を利用します。(パラメーターをシェアしても良いですが、計算の簡単化のためにあえて分けています。)
次のP32からP32は最適化する際に目的関数の微分を計算する具体的なステップです。計算に興味がない方は無視して良いです。



 面白いのは、目的関数を微分した結果は文脈語ベクトルの観測値と期待値の差分になります。観測値と期待値が一致することはモデルがよく学習できていることです。
面白いのは、目的関数を微分した結果は文脈語ベクトルの観測値と期待値の差分になります。観測値と期待値が一致することはモデルがよく学習できていることです。
ちなみに、Softmax系のモデルを最適化する際にいつもこのような観測値と期待値の差分になります。
最適化の基礎
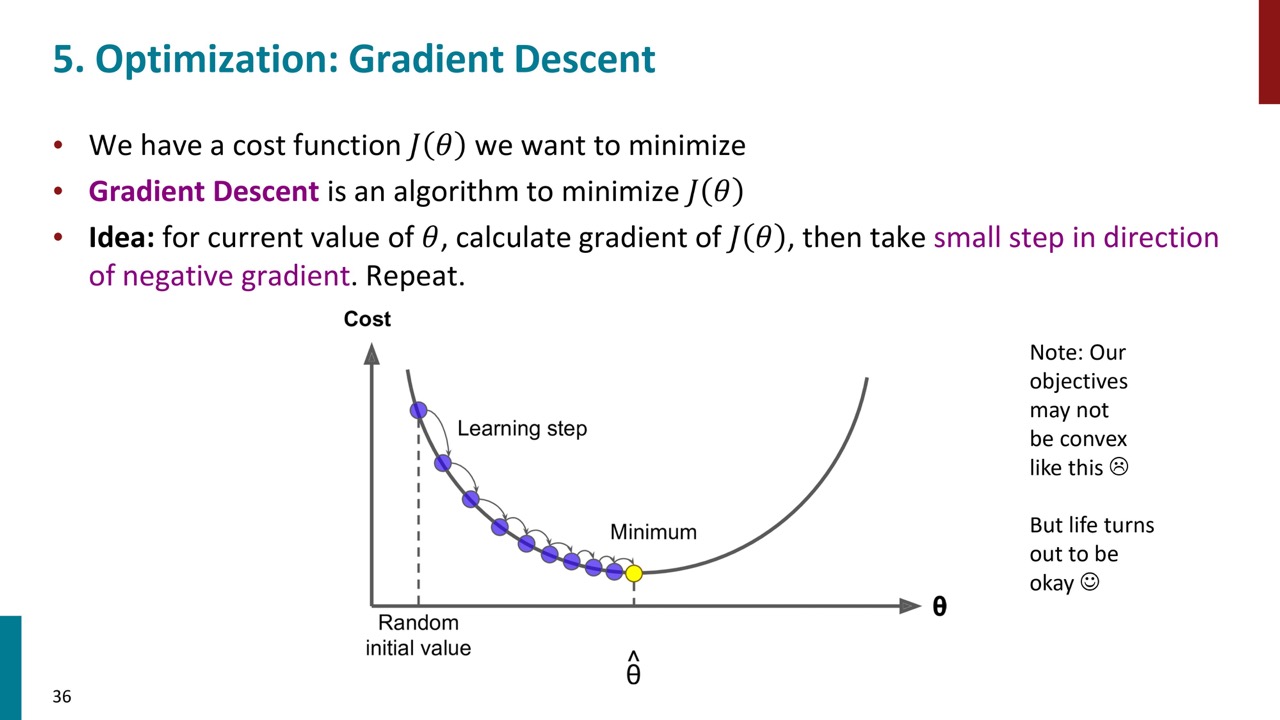 ワードベクトルの学習方法については、ランダムなワードベクトルから始め、損失関数を定義し、勾配降下法を用いて損失関数を最小化するようにベクトルを更新していきます。具体的には、現在のパラメータから勾配を計算し、その負の方向に小さなステップを進めることで、損失関数を最小化する方向に進んでいきます。
ワードベクトルの学習方法については、ランダムなワードベクトルから始め、損失関数を定義し、勾配降下法を用いて損失関数を最小化するようにベクトルを更新していきます。具体的には、現在のパラメータから勾配を計算し、その負の方向に小さなステップを進めることで、損失関数を最小化する方向に進んでいきます。
ステップサイズは調整可能で、小さすぎると計算が多くなり、大きすぎると最適解に収束しない可能性があります。また、ニューラルネットワークは一般的に凸ではないため、最適解が一意でない可能性がありますが、実際には問題なく動作します。
(勾配降下法について詳しく知りたい方は、CourseraのAndrew Ng先生の機械学習の授業の受講を強くおすすめします。)

勾配降下法とは、現在のパラメータθの値を持ち、学習率またはステップサイズαを使用して勾配の負の方向に少し移動します。これにより、新しいパラメータ値が得られます。これらはベクトルであり、各個別のパラメータは、そのパラメータに対するjの偏微分を計算することで少し更新されます。これが単純な勾配降下法のアルゴリズムです。
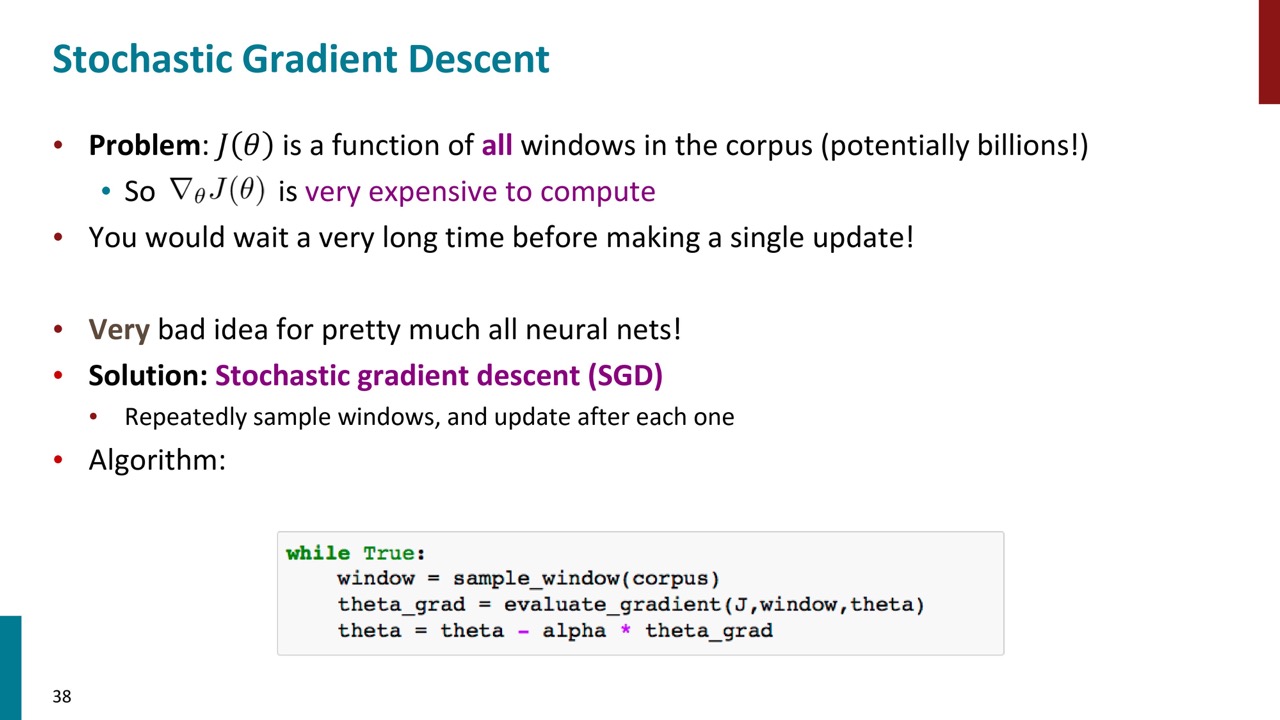 全コーパスを用いて損失関数やその勾配を計算すると、非常に時間がかかり、一度の勾配更新に長い時間を要するため、最適化が極めて遅くなります。そのため、ニューラルネットワークではほぼ100%の場合、勾配降下法ではなく確率的勾配降下法(SGD)が用いられます。SGDでは、全コーパスに基づく勾配の推定ではなく、一つまたは少数の中心語に基づく勾配の推定を行います。この推定はノイズが多く不完全ですが、それを用いてパラメータを更新します。これにより、一度のコーパス通過で何十億ものパラメータ更新が可能となり、学習速度が大幅に向上します。
全コーパスを用いて損失関数やその勾配を計算すると、非常に時間がかかり、一度の勾配更新に長い時間を要するため、最適化が極めて遅くなります。そのため、ニューラルネットワークではほぼ100%の場合、勾配降下法ではなく確率的勾配降下法(SGD)が用いられます。SGDでは、全コーパスに基づく勾配の推定ではなく、一つまたは少数の中心語に基づく勾配の推定を行います。この推定はノイズが多く不完全ですが、それを用いてパラメータを更新します。これにより、一度のコーパス通過で何十億ものパラメータ更新が可能となり、学習速度が大幅に向上します。
また、SGDは学習過程で揺れ動く特性がありますが、これが複雑なネットワークではより良い解を学習することを可能にします。したがって、確率的勾配降下法は計算速度を大幅に向上させるだけでなく、より良い結果を得ることができます。
Word Vectorを実際に見る
 最後はWord Vectorに関する簡単なデモになります。スライドがないため、説明は割愛します。
最後はWord Vectorに関する簡単なデモになります。スライドがないため、説明は割愛します。